Диаграмма потоков данных (DFD): как построить и найти узкие места

Диаграммы DFD появились в 1970-х годах из методологии структурированного анализа и проектирования. Впервые они были предложены Ларри Константином, а позже популяризированы Эдвардом Йордоном, Томом ДеМарко, Крисом Гейном и Тришей Сарсон.
Эта статья расскажет о том, что такое Data Flow Diagrams и что они собой представляют, как применяются для проектирования систем и бизнес-процессов, какие бывают и как выглядят основные обозначения элементов, какие уровни декомпозиции структуры бывают и чем будут полезны.
Что такое DFD-нотация и зачем она нужна
DFD расшифровывается как Data Flow Diagram. В русском языке термин звучит как «диаграмма потока данных».
DFD – это схема, которая наглядно отображает точки входа, выхода и последовательность шагов преобразования информационных потоков на разных уровнях. Такие диаграммы применяются в основном для проектирования информационных систем и структурного анализа.
Для создания диаграмм используется одна из систем нотаций. Наиболее распространенная нотация DFD – Гейна-Сарсон. Альтернатива – подход Йордона-ДеМарко. Но для построения модели данных вполне могут подойти и другие нотации.
В чем отличие DFD от нотаций IDEF0, UML, EPC, BPMN и других
IDEF (расшифровка: Integrated Definition for Function Modeling) — это функциональное моделирование на основе SADT (Structured Analysis and Design Technique). Диаграмма по модели IDEF0 определяет основные компоненты системы с четким разделением сторон блока, в норме предполагается не более 7 элементов на одну схему. Детализация каждого компонента осуществляется с помощью вложенных дочерних диаграмм, которые нумеруются особым образом – с указанием номера блока. Диаграмма нулевого уровня содержит только один блок. Специально для описания потоков и процессов разработан стандарт IDEF3. В нем основной фокус сделан на потоке процессов через Unit of Behavior (UOB), ссылки и сценарии. Он больше подходит для описания альтернативных путей выполнения.
BPMN (Business Process Model and Notation) — современная и широко распространенная нотация для моделирования бизнес-процессов. Здесь основной фокус сделан на последовательности действий, событиях, шлюзах (ветвлениях), пулах/дорожках и взаимодействии. Потоки данных моделируются отдельно – через объекты, входы/выходы, ассоциации данных с задачами и хранилища. Можно дополнительно показывать, какие данные читаются/записываются в задаче и как данные перемещаются между участниками – через потоки сообщений.
EPC (Event-driven Process Chain) — нотация, популярная в Европе. Центральный элемент — это события, которые чередуются с функциями. Такие схемы наглядно показывает причинно-следственные связи в формате: событие → функция → событие.
UML (Unified Modeling Language) — широко применяемый язык и нотация для моделирования программных систем. Для процессов чаще всего используется диаграмма активностей, которая похожа на диаграмму потоков с ветвлениями. В ней можно проектировать потоки данных с помощью хранилищ, пинов (входы/выходы действий) и объектов.
Максимально подробное сравнение: самые распространенные нотации моделирования бизнес-процессов.
Символы и способы нотации диаграмм потоков данных
В нотации Йордон-ДеМарко для изображения процессов используются круги. В России наиболее распространен подход Гейн-Сарсон – со скругленными прямоугольниками. Он поддерживается большинством инструментов моделирования, таких как Microsoft Visio, Lucidchart, Visual Paradigm, ConceptDraw и др.
В нотации Гейн-Сарсон используется всего четыре основных символа / обозначения. Они позволяют четко показать, откуда приходят данные, как они обрабатываются, где хранятся и куда уходят. Ниже об этих обозначениях.
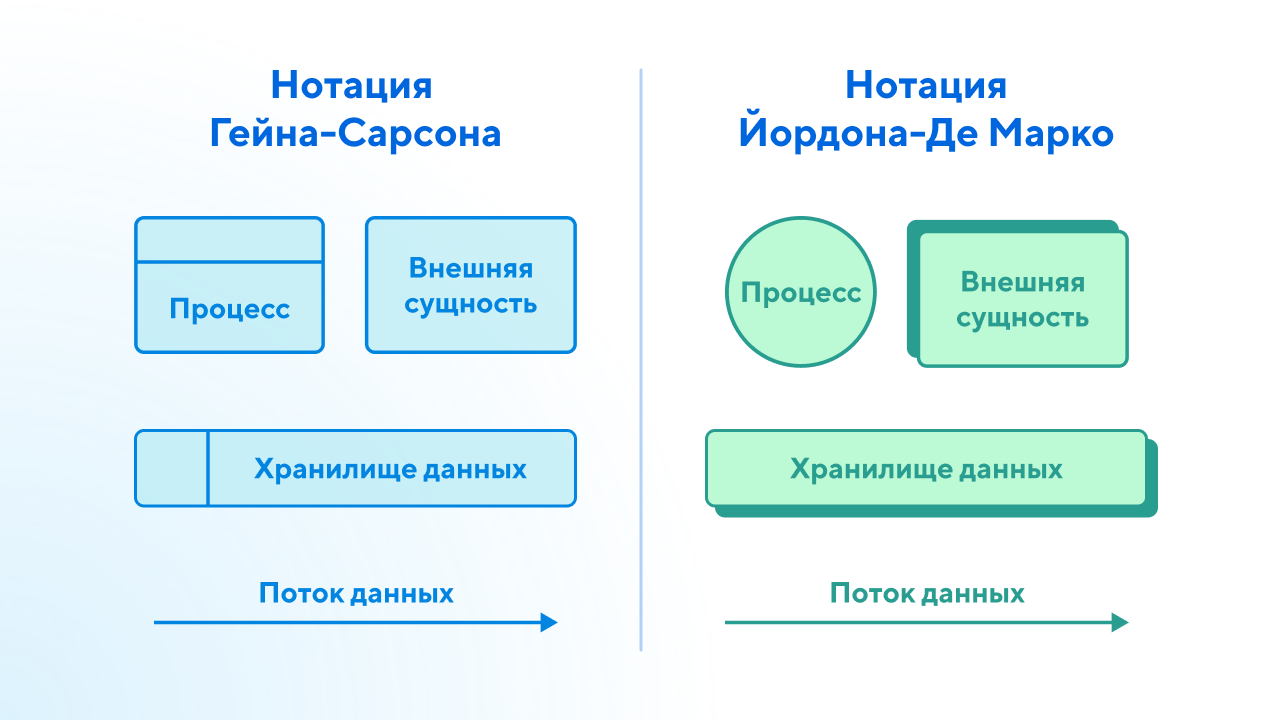
Внешние сущности / External Entity
Внешняя сущность – это получатель или источник данных.
Сущности изображаются прямоугольником, иногда с легкой тенью / контуром. К внешним сущностям относится все, что находится за пределами системы: клиент, поставщик, другой отдел, внешняя система, пользователь, клиенты. В общем понимании это и есть источники входных данных, а также получатели результатов.
Процессы / преобразование данных / Process
Процессы изображаются прямоугольниками со скругленными углами. Часто процесс разделен на три зоны:
- Верхняя — номер процесса, например, 2.3.
- Средняя — название. Обычно это глагол + объект. Пример: «Проверить заказ», «Сформировать счет».
- Нижняя — исполнитель или местоположение, опционально. Пример: «Отдел продаж» или «CRM-система».
Процесс преобразует входные данные в выходные. Внутри диаграммы этот элемент показывает действие, которое выполняется над данными – обработка, проверка, расчет, формирование документа и т.д.
Хранилища данных / Data Store
Открытый прямоугольник – он закрыт с левой стороны, но открыт с правой. Реже хранилища изображаются в виде двух параллельных горизонтальных линий.
Хранилище – это место постоянного или временного хранения данных: база данных, файл, таблица, папка, регистр. Данные могут читаться из хранилища и записываться в него.
Поток данных / Data Flow
Прямая стрелка с названием, она может быть горизонтальной или вертикальной.
Стрелки наглядно показывает перемещение потока информации между элементами. Название потока — всегда существительное, отражающее содержание. Например: «Заявка клиента», «Отчет о продажах», «Подтверждение оплаты».
Дополнительные особенности и правила нотации
- Нумерация процессов. На контекстной диаграмме (уровень 0) система изображается как один процесс. На диаграммах декомпозиции процессы нумеруются целыми числами, по аналогии с версиями ПО, в дочерних уровнях детализуются числами после точки. Номер указывается в верхней части прямоугольника процесса.
- Правила соединения элементов. Поток данных не может идти напрямую от одной внешней сущности к другой, а еще он не может соединять два хранилища напрямую (без процесса). Каждый процесс должен иметь хотя бы один выход и хотя бы один вход. Допускается дублирование внешних сущностей и хранилищ на одной диаграмме для удобства чтения, в некоторых инструментах дубликат помечается косой чертой в углу.
- Ветвление. Не используйте в DFD-диаграммах логические функции и операторы, такие как И, ИЛИ, НЕ, события или дорожки ответственности. Решения по перенаправлению потока принимаются внутри процессов.

Уровни DFD-диаграмм
Нотация предполагает поэтапное раскрытие системы через несколько уровней иерархии DFD. Такой подход позволяет последовательно переходить от общего представления к деталям, сохраняя фокус на том, как происходит движение данных внутри системы.
Контекстная диаграмма — уровень 0, концептуальный
Диаграммы верхних уровней часто называются контекстными, здесь система рассматривается как единое целое. На таких диаграммах показываются:
- основные потоки данных,
- все внешние сущности,
- границы системы.
Диаграммы верхних уровней дают общее понимание связей между функциями и сущностями, но не раскрывают внутреннюю структуру процессов.
Диаграммы уровня 1
Для построения диаграммы уровня 1:
- система декомпозируется на ключевые процессы,
- уточняются основные потоки данных между ними,
- добавляются хранилища данных.
Именно здесь начинается построение иерархии диаграмм, когда один процесс верхнего уровня раскрывается в несколько подпроцессов.
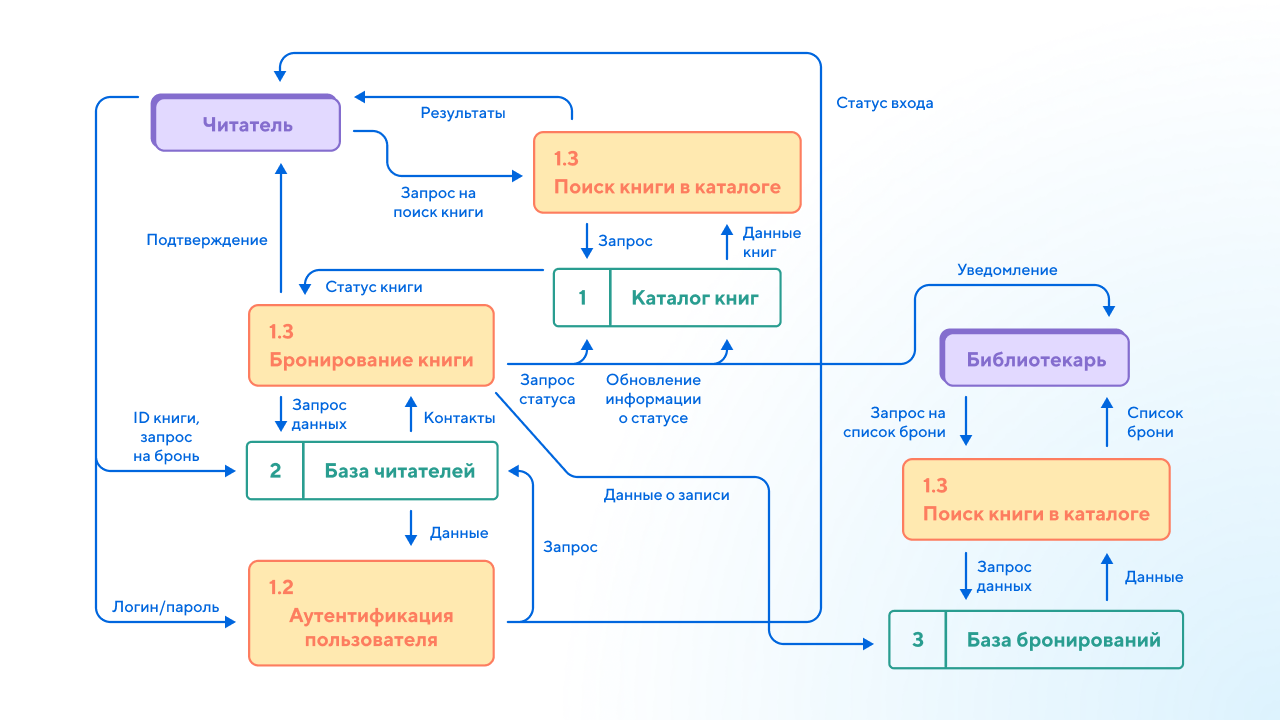
Диаграммы следующего уровня
Диаграммы следующего уровня детализируют ключевые процессы с первого уровня. При необходимости вы можете создавать и описывать сколько угодно уровней иерархии: level 2, 3, 4 и глубже.
На нижних уровнях детализации могут появляться новые связи и потоки данных, но они не должны противоречить потокам верхних уровней.
Вся модель строится как дерево, где каждый процесс может быть раскрыт на более низком уровне, и при этом обеспечивается сквозная согласованность между всеми уровнями одновременно.
Логические и физические диаграммы DFD
Диаграммы потоков данных принято разделять на два основных типа: логические и физические. Они отражают разные уровни абстракции и служат разным целям.
Логическая диаграмма DFD
Логическая диаграмма DFD показывает ключевую логику системы – что она делает с точки зрения бизнеса, не углубляясь в технические детали реализации. Она фокусируется на бизнес-процессах, событиях и необходимых потоках данных.
На логической диаграмме DFD в качестве основных элементов выступают бизнес-функции или направления деятельности, например, «Оформить отгрузку заказа», «Подтвердить поступление платежа», «Подготовить ежедневный отчет». Именно поэтому они подходят для описания бизнес-процессов. Подпроцессы можно детализировать бесконечно – по мере необходимости.
Хранилища данных отображаются как абстрактные коллекции данных – независимо от того, как они хранятся физически: в базе, файле или в общем каталоге.
Потоки данных отражают смысловое содержание информации.
Внешние сущности — это внешние участники или системы: клиенты, поставщики, регуляторы.
Логические диаграммы обычно создаются на ранних этапах проектирования программных продуктов или при планировании проектов, они служат основой для дальнейшей разработки – написания кода.
Физическая диаграмма DFD
Физическая диаграмма DFD показывает, как именно система реализована или будет реализована на практике. Она описывает техническую и организационную сторону обработки данных: какие элементы и узлы она включает, как выглядит защита данных в системе, как строятся подсистемы и т.п.
В физической диаграмме DFD в качестве процессов выступают конкретные программы, модули, ручные процедуры или операции, например: «Модуль обработки заказов в CRM», «Скрипт формирования отчета в 1С», «Ручная сверка в Excel» и пр.
Хранилища данных конкретизируются: указываются реальные базы данных, общие каталоги, файлы, формы документов, принтеры и другие физические носители.
Потоки данных могут включать конкретные форматы, протоколы передачи или способы ввода/вывода, например, «XML-файл заявки», «Данные через REST API».
Здесь часто отображаются технические компоненты: конкретные приложения, устройства, пользователи и интерфейсы.

Правила построения диаграммы потоков данных: пошаговая инструкция
DFD диаграммы строят по строгим правилам, всегда «сверху вниз». Ниже приведена пошаговая инструкция, которая поможет создать корректную, понятную и сбалансированную схему.
Шаг 1. Определите цель диаграммы и границы системы
Четко сформулируйте, какую систему или процесс вы моделируете. Определите, будет ли диаграмма логической (что делает система) или физической (как это реализовано).
Соберите требования: список входных и выходных данных, участников, документов и хранилищ.
Шаг 2. Постройте контекстную диаграмму (Level 0)
Изобразите систему как один процесс (прямоугольник со скругленными углами). Добавьте все внешние сущности (прямоугольники).
Проведите потоки данных (стрелки с названиями) от внешних элементов к процессу и от него. Не показывайте внутренние хранилища и подпроцессы на этом уровне.
Диаграмма нулевого уровня определяет только контекст и границы системы.
Шаг 3. Создайте диаграмму уровня 1 (Level 1)
Разложите контекстный процесс на основные подпроцессы – обычно от 3 до 9 элементов. Перенесите все потоки с контекстной диаграммы.
Добавьте хранилища данных (открытые прямоугольники), с которыми взаимодействуют процессы. Соедините элементы стрелками.
Шаг 4. Выполняйте дальнейшую декомпозицию на нижних уровнях
Каждый процесс с верхнего уровня может быть детализирован на отдельной диаграмме следующего уровня. При декомпозиции:
- Входящие и исходящие потоки процесса-родителя должны полностью сохраняться на дочерней диаграмме (правило баланса).
- Добавляйте новые внутренние потоки данных и хранилища только внутри этой декомпозиции.
- Останавливайте декомпозицию, когда процессы становятся элементарными – их можно описать одной мини-спецификацией или простым текстом.
Данные не могут исчезать или появляться из ниоткуда — каждый поток должен начинаться и заканчиваться у процесса.
Шаг 5. Проверьте и сбалансируйте диаграмму
Проверьте баланс между уровнями: все входы/выходы родительского процесса должны присутствовать на дочерней диаграмме.
Убедитесь в отсутствии процессов без выхода и без входа.
Проверьте читаемость: не перегружайте одну диаграмму. Рекомендуется до 7-9 процессов на один уровень.
По возможности разнесите пересекающиеся стрелки или используйте дублирование внешних сущностей / хранилищ для удобства.
Шаг 6. Документируйте и согласуйте
Для элементарных процессов подготовьте мини-спецификации – описание алгоритма, формулы, правила.
Согласуйте диаграммы с заказчиком и экспертами.
При необходимости создайте физическую версию DFD на основе логической.
Следующим шагом после создания DFD-диаграммы будет создание спецификаций процессов нижнего уровня для полной детализации всех механизмов информационной системы.

Типичные ошибки при построении DFD
- Нарушение баланса между уровнями иерархии. Входящие и исходящие потоки данных родительского процесса не полностью переносятся на дочернюю диаграмму или, наоборот, на нижнем уровне появляются новые потоки, которых не было на верхнем. Из-за этого модель становится несогласованной.
- Прямое соединение двух хранилищ данных или двух внешних сущностей. Такое соединение нарушает основное правило DFD и создает иллюзию перемещения данных без какой-либо обработки. Обработка или изменение есть всегда.
- Процесс без входа или без выхода – «черная дыра» или «чудо». Это делает процесс логически невозможным.
- Перегрузка диаграммы слишком большим количеством процессов. Если на одной диаграмме размещается 10 и более процессов, то это сильно затрудняет ее чтение и понимание.
- Неправильное именование элементов. Из-за этого теряется смысл и понимание диаграммы.
- Использование логических конструкций, событий или ответственности на DFD. Такая диаграмма не предназначена для показа последовательности и логики принятия решений. «Логика» должна быть зашита внутри одного из процессов.
- Создание физической диаграммы вместо логической на этапе анализа требований. Это делает диаграмму непригодной для обсуждения с бизнес-заказчиком.
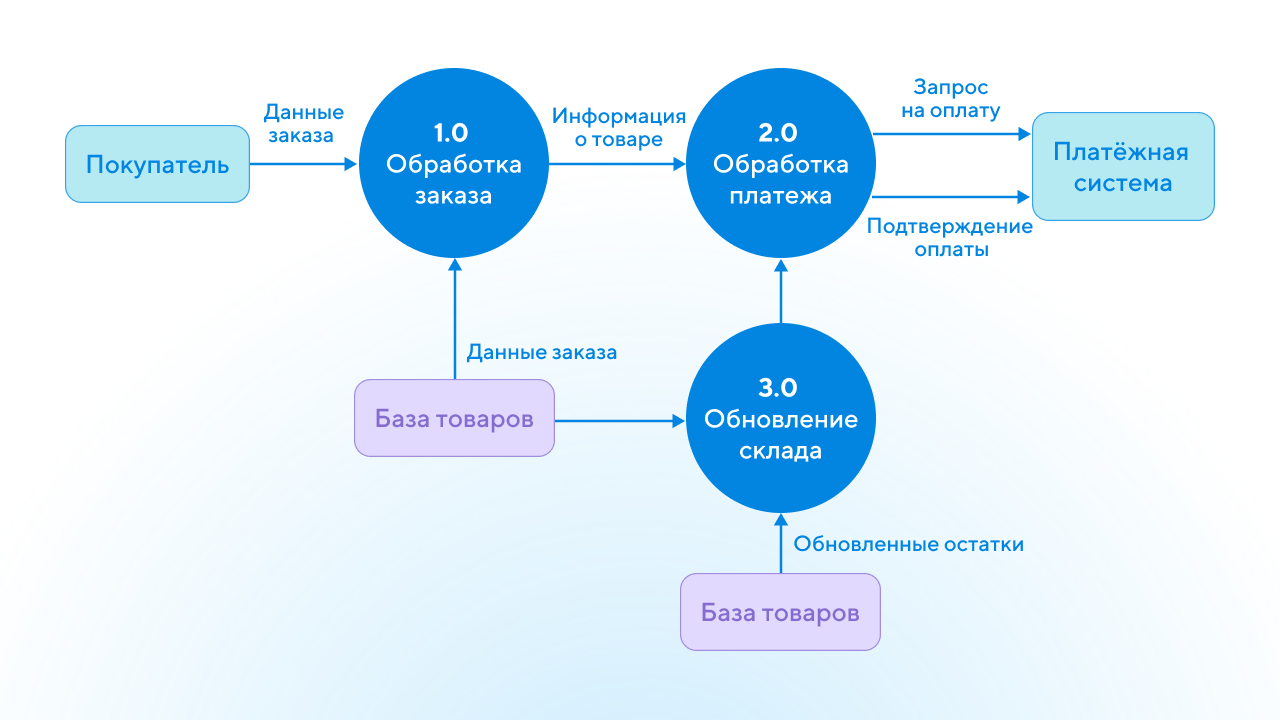
Шаблоны и примеры диаграмм DFD


Инструменты для создания DFD-диаграмм
Имеющиеся на рынке инструменты можно условно разделить на следующие группы:
- Бесплатные и open-source конструкторы диаграмм. Эта группа предлагает максимальную доступность без затрат и подходит для индивидуальной работы, обучения и небольших проектов.
Примеры: draw (diagrams.net, работает онлайн или в виде десктопных приложений), Merit Modeler (полностью бесплатное ПО для моделирования диаграмм данных и потоков), Dia (простой open-source редактор диаграмм с поддержкой DFD). - Облачные платформы. Инструменты и сервисы, ориентированные на командную работу в реальном времени, не требуют установки и обновления ПО, используют нейросети / ИИ для ускорения генерации диаграмм, но часто работают по подписке.
Примеры: Lucidchart, Miro, SmartDraw и пр. Многие из них невозможно оплатить из России. - Профессиональные desktop-приложения. Это инструменты для серьезного моделирования, часто используемые в крупных компаниях и при комплексном проектировании систем.
Примеры: Автограф (отечественный продукт), Microsoft Visio, Visual Paradigm, ConceptDraw DIAGRAM, Luna Modeler (софт ориентирован на SQL базы данных, есть альтернативы и для других типов БД) и т.п. - Любые непрофильные графические редакторы. Растровые или векторные редакторы, работающие online или offline, в составе офисных пакетов или без них. Главное – это возможность отрисовки фигур и стрелок. Основная проблема – минимальная интерактивность. Если переместить любой из элементов, придется заново нарисовать все связи.
Примеры: МойОфис Схема, LibreOffice Draw и т.п. - Профильные системы для проектирования и анализа потоков данных. Примеры: Loginom (Россия), AllFusion Process Modeler и прочие.
Для построения контекстных диаграмм и диаграмм нижнего уровня используют профильные инструменты и редакторы. В отличие от BPMN-нотации или UML, для логики DFD нет готовых решений по автоматизации процессов. Чтобы ваши схемы заработали в жизни, их нужно будет настроить в ваших информационных системах вручную.
Например, в Projecto можно структурировать процессы через группы, настраивать этапы, назначать ответственных и участников, а также управлять правами перемещения задач между статусами. Это помогает приблизить логическую модель к реальной работе, сделать процессы прозрачнее и упростить контроль их выполнения. Дополнительно система позволяет фиксировать сроки и отслеживать загрузку команды, что упрощает планирование и выявление узких мест. А единое пространство для задач и коммуникаций снижает риск потери информации и ускоряет взаимодействие между участниками процесса.

 1 мин
Теория
Контроль работы сотрудников – виды, методы и инструменты
Рассказываем про актуальность контроля в современных компаниях, о типах корпоративных культур, а также видах, методах и инструментах контроля…
1 мин
Теория
Контроль работы сотрудников – виды, методы и инструменты
Рассказываем про актуальность контроля в современных компаниях, о типах корпоративных культур, а также видах, методах и инструментах контроля…
 1 мин
Теория
Манифест Agile: основные принципы и ценности, история создания
Что на самом деле стоит за Agile? Манифест из 4 ценностей и 12 принципов. Никаких детализаций и методологий,…
1 мин
Теория
Манифест Agile: основные принципы и ценности, история создания
Что на самом деле стоит за Agile? Манифест из 4 ценностей и 12 принципов. Никаких детализаций и методологий,…
 1 мин
Теория
Система управления проектами в 2026 году: какой инструмент для управления задачами и проектами выбрать
Не знаете, какую систему управления проектами выбрать? Мы изучили российские сервисы, их возможности и ограничения, чтобы сэкономить вам…
1 мин
Теория
Система управления проектами в 2026 году: какой инструмент для управления задачами и проектами выбрать
Не знаете, какую систему управления проектами выбрать? Мы изучили российские сервисы, их возможности и ограничения, чтобы сэкономить вам…